개요
이 튜토리얼에서는 LangGraph를 사용하여 retrieval 에이전트를 구축합니다. LangChain은 LangGraph 프리미티브를 사용하여 구현된 내장 에이전트 구현을 제공합니다. 더 깊은 수준의 커스터마이징이 필요한 경우, LangGraph에서 직접 에이전트를 구현할 수 있습니다. 이 가이드는 retrieval 에이전트의 구현 예시를 보여줍니다. Retrieval 에이전트는 LLM이 vectorstore에서 컨텍스트를 검색할지 아니면 사용자에게 직접 응답할지 결정하도록 하고 싶을 때 유용합니다. 튜토리얼을 마치면 다음 작업들을 완료하게 됩니다:- 검색에 사용할 문서를 가져와서 전처리하기
- 의미론적 검색을 위해 문서를 인덱싱하고 에이전트를 위한 retriever 도구 생성하기
- retriever 도구를 사용할 시점을 결정할 수 있는 agentic RAG 시스템 구축하기
개념
다음 개념들을 다룹니다:- 문서 로더, 텍스트 분할기, embeddings, 벡터 스토어를 사용한 Retrieval
- state, 노드, 엣지, conditional 엣지를 포함한 LangGraph Graph API
설정
필요한 패키지를 다운로드하고 API 키를 설정합니다:LangSmith에 가입하여 LangGraph 프로젝트의 문제를 빠르게 발견하고 성능을 개선하세요. LangSmith를 사용하면 LangGraph로 구축한 LLM 앱을 추적 데이터를 통해 디버깅, 테스트, 모니터링할 수 있습니다.
1. 문서 전처리
- RAG 시스템에 사용할 문서를 가져옵니다. Lilian Weng의 훌륭한 블로그에서 가장 최근의 페이지 세 개를 사용하겠습니다. 먼저
WebBaseLoader유틸리티를 사용하여 페이지의 콘텐츠를 가져옵니다:
- 가져온 문서를 vectorstore에 인덱싱하기 위해 더 작은 청크로 분할합니다:
2. retriever 도구 생성
이제 분할된 문서가 있으므로, 의미론적 검색에 사용할 벡터 스토어에 인덱싱할 수 있습니다.- 인메모리 벡터 스토어와 OpenAI embeddings를 사용합니다:
- LangChain의 사전 구축된
create_retriever_tool을 사용하여 retriever 도구를 생성합니다:
- 도구를 테스트합니다:
3. 쿼리 생성
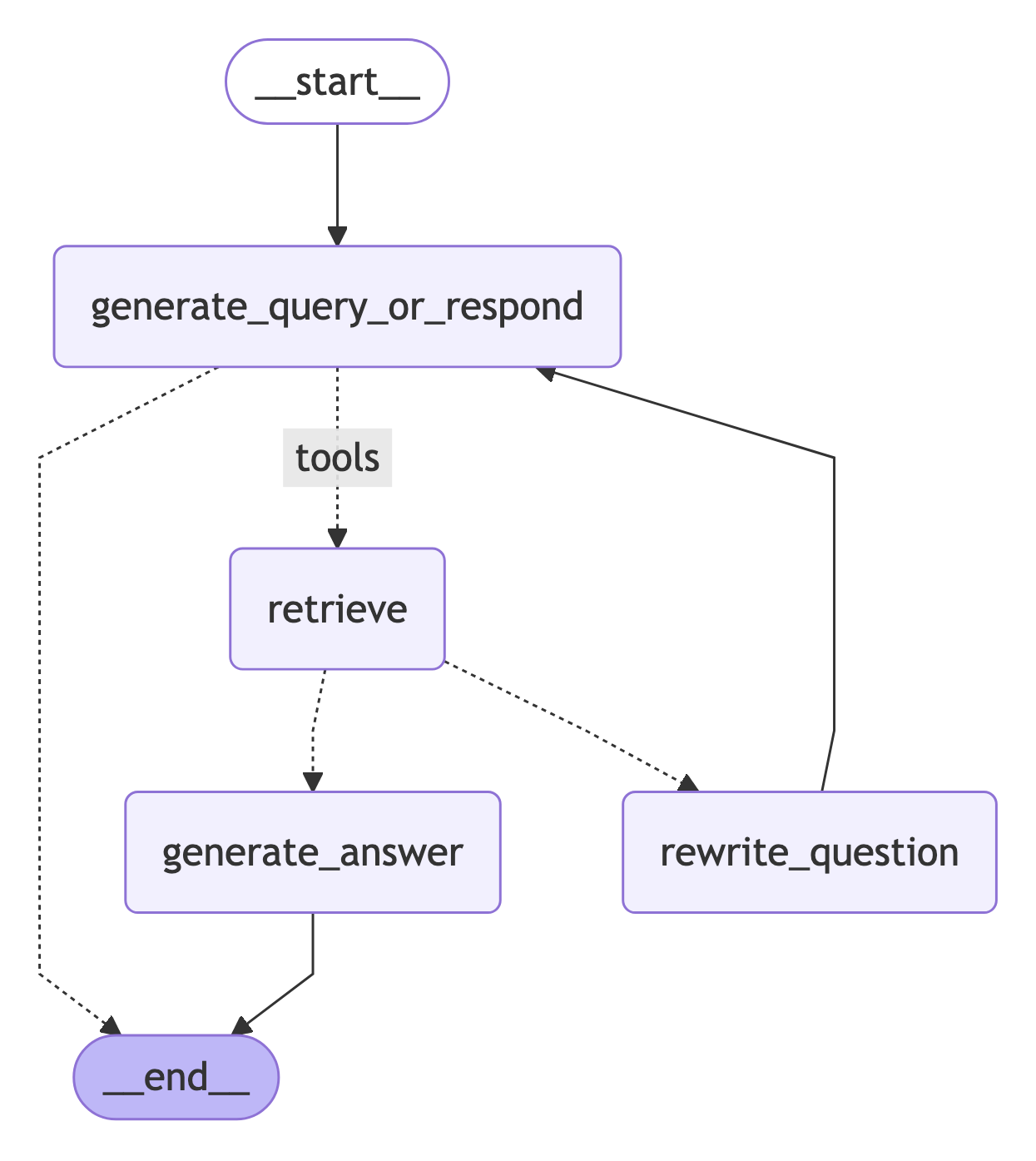
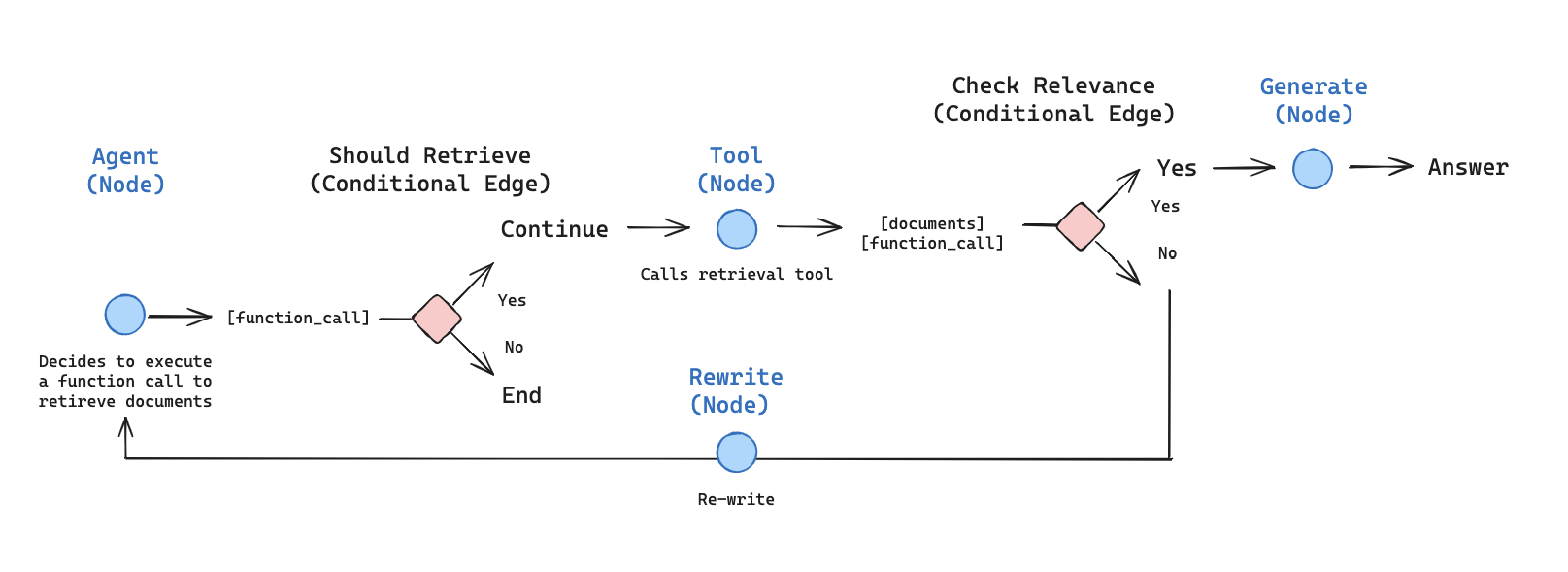
이제 agentic RAG 그래프를 위한 컴포넌트(노드와 엣지)를 구축하기 시작합니다. 컴포넌트들은MessagesState에서 작동합니다 — 채팅 메시지 리스트를 포함하는 messages 키가 있는 그래프 state입니다.
generate_query_or_respond노드를 구축합니다. 현재 그래프 state(메시지 리스트)를 기반으로 LLM을 호출하여 응답을 생성합니다. 입력 메시지가 주어지면, retriever 도구를 사용하여 검색할지 아니면 사용자에게 직접 응답할지 결정합니다..bind_tools를 통해 앞서 생성한retriever_tool에 대한 접근 권한을 채팅 모델에 부여하고 있습니다:
- 임의의 입력으로 시도해봅니다:
- 의미론적 검색이 필요한 질문을 해봅니다:
4. 문서 평가
- 검색된 문서가 질문과 관련이 있는지 판단하기 위한 conditional 엣지 —
grade_documents—를 추가합니다. 문서 평가를 위해 구조화된 출력 스키마GradeDocuments가 있는 모델을 사용합니다.grade_documents함수는 평가 결정에 따라 이동할 노드의 이름(generate_answer또는rewrite_question)을 반환합니다:
- 도구 응답에서 관련 없는 문서로 실행해봅니다:
- 관련 문서가 그렇게 분류되는지 확인합니다:
5. 질문 재작성
rewrite_question노드를 구축합니다. retriever 도구는 잠재적으로 관련 없는 문서를 반환할 수 있으며, 이는 원래 사용자 질문을 개선할 필요가 있음을 나타냅니다. 이를 위해rewrite_question노드를 호출합니다:
- 시도해봅니다:
6. 답변 생성
generate_answer노드를 구축합니다: 평가 검사를 통과하면, 원래 질문과 검색된 컨텍스트를 기반으로 최종 답변을 생성할 수 있습니다:
- 시도해봅니다:
7. 그래프 조립
이제 모든 노드와 엣지를 완전한 그래프로 조립합니다:generate_query_or_respond로 시작하여retriever_tool을 호출해야 하는지 결정합니다tools_condition을 사용하여 다음 단계로 라우팅합니다:generate_query_or_respond가tool_calls를 반환한 경우,retriever_tool을 호출하여 컨텍스트를 검색합니다- 그렇지 않으면 사용자에게 직접 응답합니다
- 질문과의 관련성에 대해 검색된 문서 콘텐츠를 평가하고(
grade_documents) 다음 단계로 라우팅합니다:- 관련이 없는 경우,
rewrite_question을 사용하여 질문을 다시 작성한 다음generate_query_or_respond를 다시 호출합니다 - 관련이 있는 경우,
generate_answer로 진행하여 검색된 문서 컨텍스트가 포함된ToolMessage를 사용하여 최종 응답을 생성합니다
- 관련이 없는 경우,