

Alpha Notice: These docs cover the v1-alpha release. Content is incomplete and subject to change.For the latest stable version, see the current LangGraph Python or LangGraph JavaScript docs.
checkpoint를 저장합니다. 이러한 체크포인트는 thread에 저장되며, 그래프 실행 후에 접근할 수 있습니다. threads를 통해 실행 후 그래프 상태에 접근할 수 있기 때문에, human-in-the-loop, 메모리, 시간 여행, 결함 허용성 등 여러 강력한 기능이 모두 가능합니다. 아래에서는 이러한 각 개념을 더 자세히 설명하겠습니다.
LangGraph API는 자동으로 체크포인팅을 처리합니다
LangGraph API를 사용할 때는 체크포인터를 수동으로 구현하거나 구성할 필요가 없습니다. API가 백그라운드에서 모든 영속성 인프라를 자동으로 처리합니다.
Threads
Thread는 체크포인터가 저장하는 각 체크포인트에 할당된 고유 ID 또는 스레드 식별자입니다. Thread는 일련의 runs의 누적된 상태를 포함합니다. Run이 실행되면, 어시스턴트의 기본 그래프의 state가 스레드에 영속화됩니다. 체크포인터와 함께 그래프를 호출할 때, config의configurable 부분에 thread_id를 반드시 지정해야 합니다.
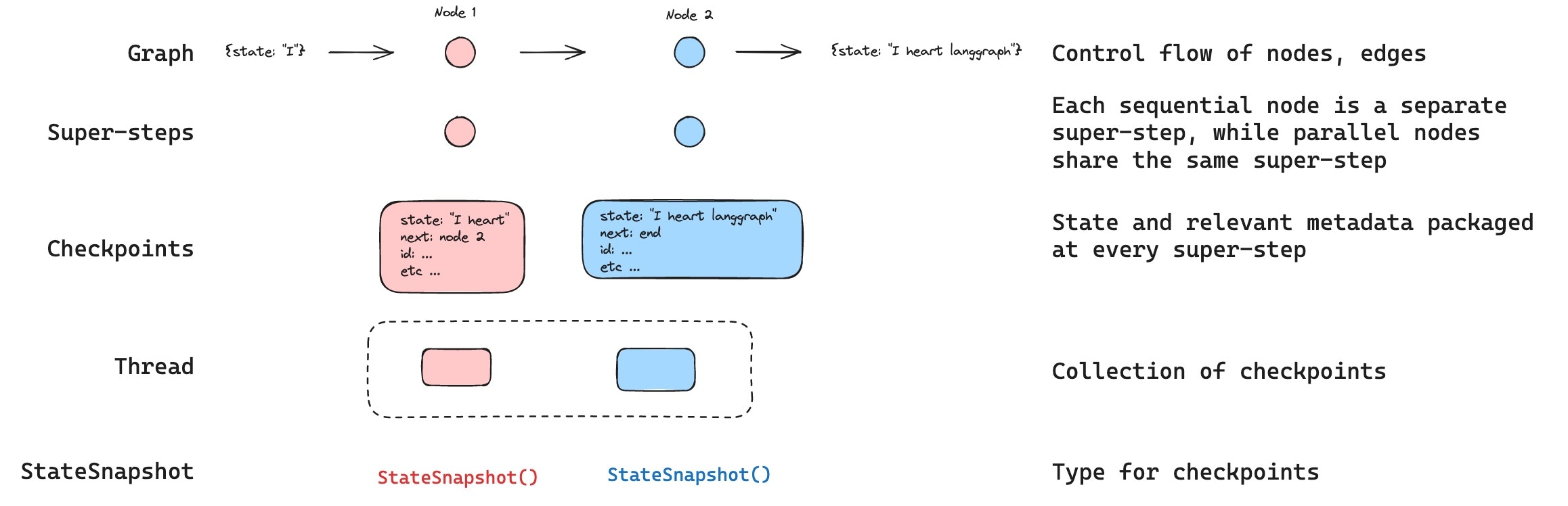
Checkpoints
특정 시점의 스레드 상태를 체크포인트라고 합니다. Checkpoint는 각 슈퍼 스텝마다 저장된 그래프 상태의 스냅샷이며, 다음의 주요 속성을 가진StateSnapshot 객체로 표현됩니다:
config: 이 체크포인트와 연관된 설정입니다.metadata: 이 체크포인트와 연관된 메타데이터입니다.values: 이 시점의 상태 채널 값들입니다.next그래프에서 다음에 실행될 노드 이름의 튜플입니다.tasks: 다음에 실행될 작업에 대한 정보를 포함하는PregelTask객체의 튜플입니다. 이전에 스텝이 시도된 경우 오류 정보가 포함됩니다. 그래프가 노드 내에서 동적으로 중단된 경우, tasks에는 중단과 관련된 추가 데이터가 포함됩니다.
START가 다음에 실행될 노드로 설정된 빈 체크포인트- 사용자 입력
{'foo': '', 'bar': []}와node_a가 다음에 실행될 노드로 설정된 체크포인트 node_a의 출력{'foo': 'a', 'bar': ['a']}와node_b가 다음에 실행될 노드로 설정된 체크포인트node_b의 출력{'foo': 'b', 'bar': ['a', 'b']}와 다음에 실행될 노드가 없는 체크포인트
bar 채널에 리듀서가 있기 때문에 bar 채널 값에는 두 노드의 출력이 모두 포함되어 있습니다.
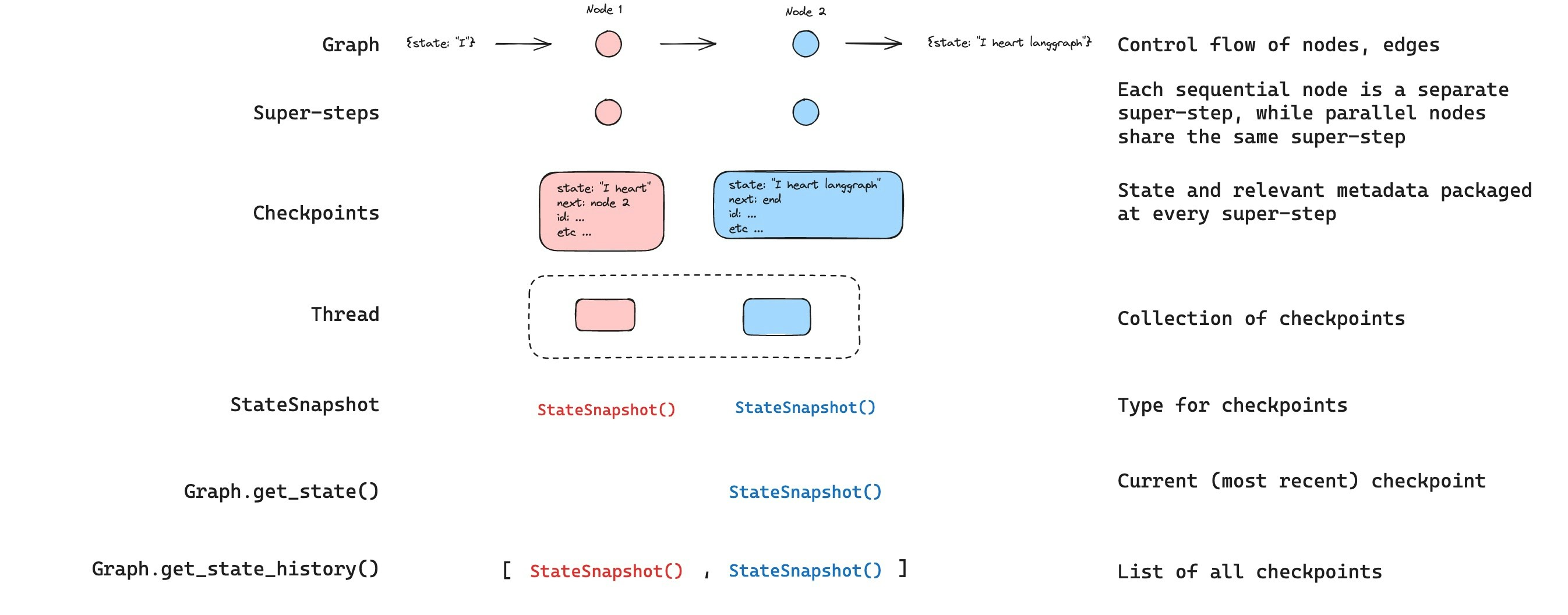
Get state
저장된 그래프 상태와 상호작용할 때는 thread identifier를 반드시 지정해야 합니다.graph.get_state(config)를 호출하여 그래프의 최신 상태를 확인할 수 있습니다. 이는 config에 제공된 스레드 ID와 연관된 최신 체크포인트 또는 제공된 경우 스레드에 대한 체크포인트 ID와 연관된 체크포인트에 해당하는 StateSnapshot 객체를 반환합니다.
get_state의 출력은 다음과 같습니다:
Get state history
graph.get_state_history(config)를 호출하여 주어진 스레드에 대한 그래프 실행의 전체 히스토리를 가져올 수 있습니다. 이는 config에 제공된 스레드 ID와 연관된 StateSnapshot 객체의 리스트를 반환합니다. 중요한 점은, 체크포인트가 시간순으로 정렬되며 가장 최근의 체크포인트 / StateSnapshot이 리스트의 첫 번째에 위치한다는 것입니다.
get_state_history의 출력은 다음과 같습니다:
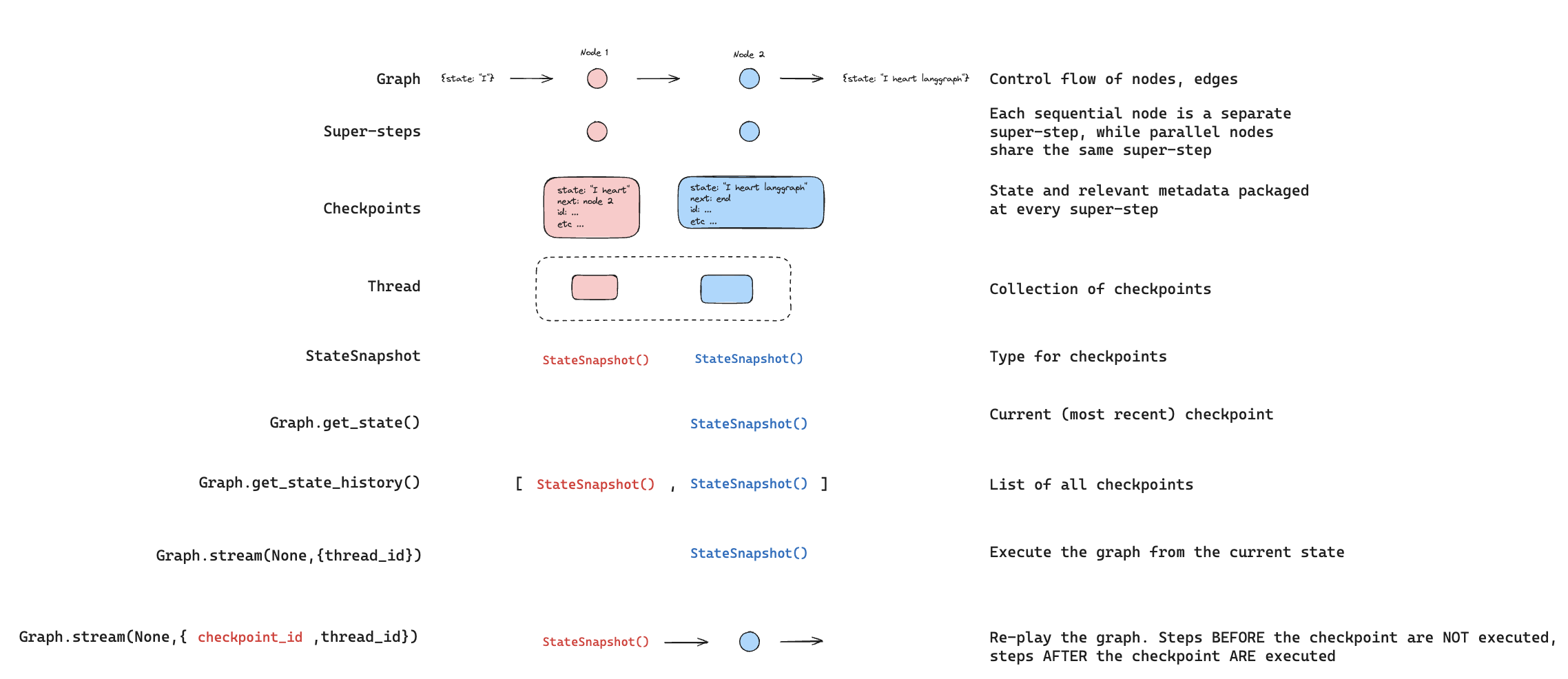
Replay
이전 그래프 실행을 재생하는 것도 가능합니다.thread_id와 checkpoint_id로 그래프를 invoke하면, checkpoint_id에 해당하는 체크포인트 이전에 실행된 스텝을 _재생_하고, 체크포인트 이후의 스텝만 실행합니다.
thread_id는 스레드의 ID입니다.checkpoint_id는 스레드 내의 특정 체크포인트를 참조하는 식별자입니다.
configurable 부분에 이들을 전달해야 합니다:
checkpoint_id 이전의 스텝에만 해당됩니다. checkpoint_id 이후의 모든 스텝은 이전에 실행된 적이 있더라도 실행됩니다(즉, 새로운 분기). 재생에 대한 자세한 내용은 시간 여행 사용 방법 가이드를 참조하세요.
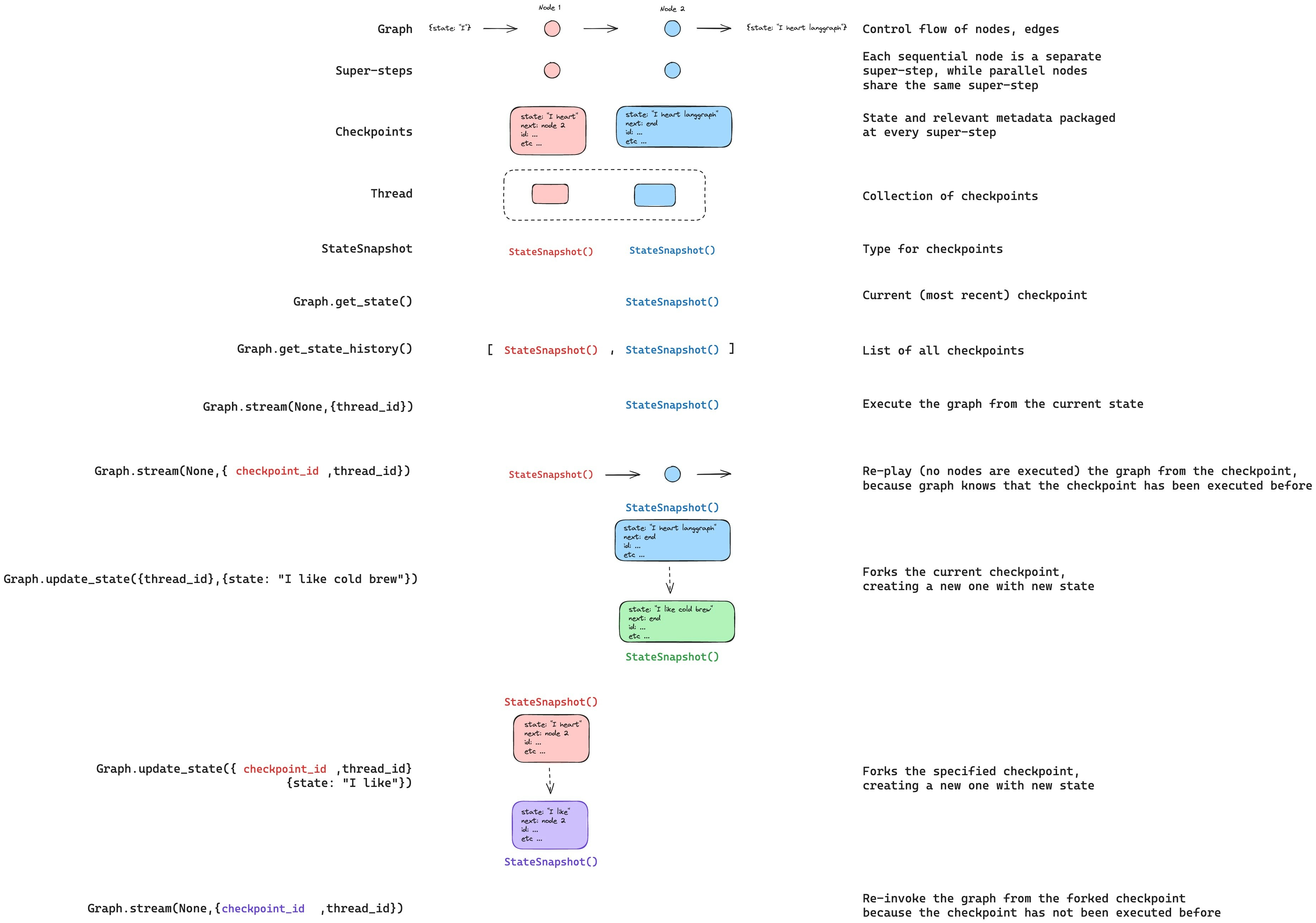
Update state
특정checkpoints에서 그래프를 재생하는 것 외에도, 그래프 상태를 _편집_할 수도 있습니다. 이는 graph.update_state()를 사용하여 수행합니다. 이 메서드는 세 가지 인수를 받습니다:
config
config에는 업데이트할 스레드를 지정하는 thread_id가 포함되어야 합니다. thread_id만 전달되면 현재 상태를 업데이트(또는 분기)합니다. 선택적으로 checkpoint_id 필드를 포함하면 선택된 체크포인트를 분기합니다.
values
상태를 업데이트하는 데 사용될 값들입니다. 이 업데이트는 노드의 모든 업데이트가 처리되는 것과 정확히 동일하게 처리됩니다. 즉, 이러한 값들은 그래프 상태의 일부 채널에 대해 정의된 경우 reducer 함수로 전달됩니다. 따라서 update_state는 모든 채널의 채널 값을 자동으로 덮어쓰지 않고, 리듀서가 없는 채널에 대해서만 덮어씁니다. 예제를 통해 살펴보겠습니다.
다음 스키마로 그래프 상태를 정의했다고 가정해봅시다(위의 전체 예제 참조):
foo 키(채널)는 완전히 변경됩니다(해당 채널에 대해 지정된 리듀서가 없으므로 update_state가 덮어씁니다). 그러나 bar 키에 대해서는 리듀서가 지정되어 있으므로 bar의 상태에 "b"를 추가합니다.
as_node
update_state를 호출할 때 선택적으로 지정할 수 있는 마지막 항목은 as_node입니다. 제공하면 업데이트가 노드 as_node에서 온 것처럼 적용됩니다. as_node가 제공되지 않으면, 모호하지 않은 경우 상태를 업데이트한 마지막 노드로 설정됩니다. 이것이 중요한 이유는 다음에 실행할 스텝이 업데이트를 제공한 마지막 노드에 따라 달라지기 때문이며, 따라서 다음에 실행할 노드를 제어하는 데 사용할 수 있습니다. 상태 분기에 대한 자세한 내용은 시간 여행 사용 방법 가이드를 참조하세요.
Memory Store
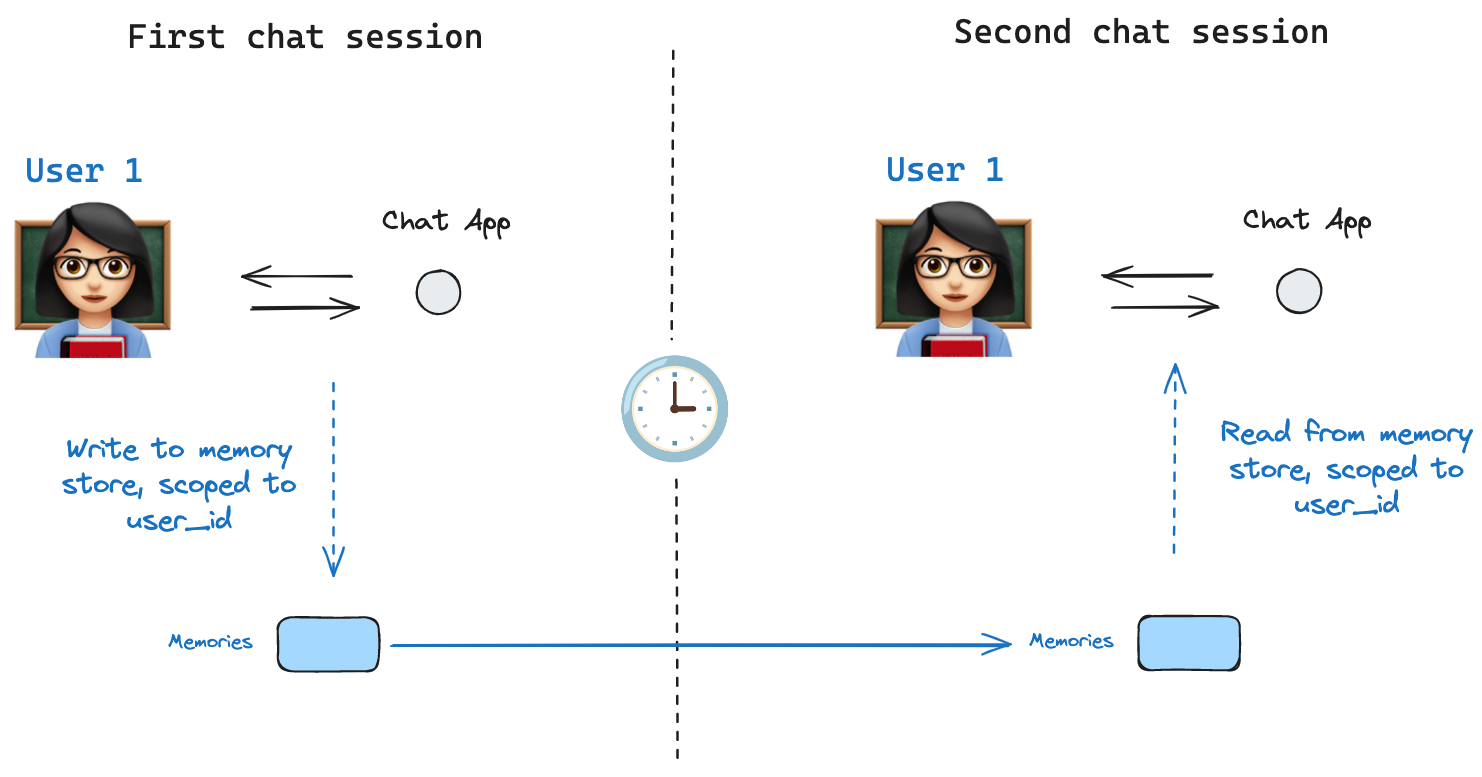
Store 인터페이스가 필요한 이유입니다. 예시로, 스레드 간에 사용자에 대한 정보를 저장하기 위해 InMemoryStore를 정의할 수 있습니다. 이전처럼 체크포인터와 함께, 그리고 새로운 in_memory_store 변수와 함께 그래프를 컴파일하기만 하면 됩니다.
LangGraph API는 자동으로 store를 처리합니다
LangGraph API를 사용할 때는 store를 수동으로 구현하거나 구성할 필요가 없습니다. API가 백그라운드에서 모든 스토리지 인프라를 자동으로 처리합니다.
Basic Usage
먼저, LangGraph를 사용하지 않고 이것만 단독으로 살펴보겠습니다.tuple로 네임스페이스화되며, 이 특정 예제에서는 (<user_id>, "memories")가 됩니다. 네임스페이스는 어떤 길이든 될 수 있고 무엇이든 나타낼 수 있으며, 사용자별일 필요는 없습니다.
store.put 메서드를 사용하여 store의 네임스페이스에 메모리를 저장합니다. 이 작업을 수행할 때 위에서 정의한 네임스페이스와 메모리에 대한 키-값 쌍을 지정합니다: 키는 메모리의 고유 식별자(memory_id)이고 값(딕셔너리)은 메모리 자체입니다.
store.search 메서드를 사용하여 네임스페이스의 메모리를 읽을 수 있으며, 주어진 사용자에 대한 모든 메모리를 리스트로 반환합니다. 가장 최근 메모리가 리스트의 마지막에 위치합니다.
Item)입니다. 위와 같이 .dict를 통해 변환하여 딕셔너리로 액세스할 수 있습니다.
속성은 다음과 같습니다:
value: 이 메모리의 값(그 자체가 딕셔너리)key: 이 네임스페이스에서 이 메모리에 대한 고유 키namespace: 이 메모리 타입의 네임스페이스인 문자열 리스트created_at: 이 메모리가 생성된 시간의 타임스탬프updated_at: 이 메모리가 업데이트된 시간의 타임스탬프
Semantic Search
단순한 검색을 넘어, store는 의미론적 검색도 지원하여 정확히 일치하는 항목이 아닌 의미를 기반으로 메모리를 찾을 수 있습니다. 이를 활성화하려면 임베딩 모델로 store를 구성하세요:fields 매개변수를 구성하거나 메모리를 저장할 때 index 매개변수를 지정하여 메모리의 어떤 부분을 임베딩할지 제어할 수 있습니다:
Using in LangGraph
모든 준비가 완료되면 LangGraph에서in_memory_store를 사용합니다. in_memory_store는 체크포인터와 함께 작동합니다: 위에서 설명한 것처럼 체크포인터는 상태를 스레드에 저장하고, in_memory_store는 스레드 간에 접근하기 위한 임의의 정보를 저장할 수 있게 합니다. 다음과 같이 체크포인터와 in_memory_store 모두와 함께 그래프를 컴파일합니다.
thread_id와 함께 그래프를 호출하고, 위에서 보여준 것처럼 이 특정 사용자에게 메모리를 네임스페이스화하는 데 사용할 user_id도 함께 호출합니다.
store: BaseStore와 config: RunnableConfig를 전달하여 _모든 노드_에서 in_memory_store와 user_id에 액세스할 수 있습니다. 다음은 노드에서 의미론적 검색을 사용하여 관련 메모리를 찾는 방법입니다:
store.search 메서드를 사용하여 메모리를 가져올 수도 있습니다. 메모리는 딕셔너리로 변환할 수 있는 객체 리스트로 반환됩니다.
user_id가 동일하면 동일한 메모리에 여전히 액세스할 수 있습니다.
langgraph.json 파일에 인덱싱 설정을 구성해야 합니다. 예를 들어:
Checkpointer libraries
내부적으로 체크포인팅은 BaseCheckpointSaver 인터페이스를 준수하는 체크포인터 객체에 의해 구동됩니다. LangGraph는 여러 체크포인터 구현을 제공하며, 모두 독립적이고 설치 가능한 라이브러리를 통해 구현됩니다:langgraph-checkpoint: 체크포인터 saver의 기본 인터페이스(BaseCheckpointSaver)와 직렬화/역직렬화 인터페이스(SerializerProtocol)입니다. 실험을 위한 인메모리 체크포인터 구현(InMemorySaver)을 포함합니다. LangGraph에는langgraph-checkpoint가 포함되어 있습니다.langgraph-checkpoint-sqlite: SQLite 데이터베이스를 사용하는 LangGraph 체크포인터 구현(SqliteSaver / AsyncSqliteSaver)입니다. 실험 및 로컬 워크플로우에 이상적입니다. 별도로 설치해야 합니다.langgraph-checkpoint-postgres: LangGraph Platform에서 사용되는 Postgres 데이터베이스를 사용하는 고급 체크포인터(PostgresSaver / AsyncPostgresSaver)입니다. 프로덕션 사용에 이상적입니다. 별도로 설치해야 합니다.
Checkpointer interface
각 체크포인터는 BaseCheckpointSaver 인터페이스를 준수하며 다음 메서드를 구현합니다:.put- 체크포인트를 구성 및 메타데이터와 함께 저장합니다..put_writes- 체크포인트에 연결된 중간 쓰기를 저장합니다(즉, 보류 중인 쓰기)..get_tuple- 주어진 구성(thread_id및checkpoint_id)에 대한 체크포인트 튜플을 가져옵니다. 이는graph.get_state()에서StateSnapshot을 채우는 데 사용됩니다..list- 주어진 구성 및 필터 기준과 일치하는 체크포인트를 나열합니다. 이는graph.get_state_history()에서 상태 히스토리를 채우는 데 사용됩니다.
.ainvoke, .astream, .abatch를 통한 그래프 실행)과 함께 사용되는 경우, 위 메서드의 비동기 버전이 사용됩니다(.aput, .aput_writes, .aget_tuple, .alist).
그래프를 비동기적으로 실행하려면
InMemorySaver 또는 Sqlite/Postgres 체크포인터의 비동기 버전인 AsyncSqliteSaver / AsyncPostgresSaver 체크포인터를 사용할 수 있습니다.Serializer
체크포인터가 그래프 상태를 저장할 때, 상태의 채널 값을 직렬화해야 합니다. 이는 serializer 객체를 사용하여 수행됩니다.langgraph_checkpoint는 serializer를 구현하기 위한 protocol을 정의하고 LangChain 및 LangGraph primitives, datetime, enum 등을 포함한 다양한 타입을 처리하는 기본 구현(JsonPlusSerializer)을 제공합니다.
Serialization with pickle
기본 serializer인 JsonPlusSerializer는 내부적으로 ormsgpack과 JSON을 사용하며, 이는 모든 타입의 객체에 적합하지 않습니다.
현재 msgpack 인코더에서 지원하지 않는 객체(예: Pandas dataframe)에 대해 pickle로 대체하려면 JsonPlusSerializer의 pickle_fallback 인수를 사용할 수 있습니다:
Encryption
체크포인터는 선택적으로 모든 영속화된 상태를 암호화할 수 있습니다. 이를 활성화하려면EncryptedSerializer의 인스턴스를 모든 BaseCheckpointSaver 구현의 serde 인수에 전달하세요. 암호화된 serializer를 생성하는 가장 쉬운 방법은 LANGGRAPH_AES_KEY 환경 변수에서 AES 키를 읽는 from_pycryptodome_aes를 통하는 것입니다(또는 key 인수를 받습니다):
LANGGRAPH_AES_KEY가 있으면 암호화가 자동으로 활성화되므로 환경 변수만 제공하면 됩니다. CipherProtocol을 구현하고 EncryptedSerializer에 제공하여 다른 암호화 방식을 사용할 수 있습니다.